脏编码
Carson Gross
“编写干净代码是你称自己为专业人士必须做的事。没有合理的借口做不到你的最好。” Clean Code
在本文中,我想谈谈我是如何编写代码的。我将我的方法称为“脏编码”,因为我经常违背 Clean Code 的推荐,这是一种流行的编写代码的方法。
现在,我并不真的认为我的代码那么脏:在某些地方有点粗糙,但总体上我对它很满意,并且发现它足够容易维护,质量水平合理。
我也不是试图通过这篇文章说服 你 来脏编码。相反,我想展示用这种方式编写合理成功的软件是可能的,并且我希望在软件方法论讨论中提供一些平衡。
我已经编程一段时间了,我见过各种构建软件的方法都奏效。有些人热爱面向对象编程(我喜欢它),其他非常聪明的人讨厌它。有些人喜欢动态语言的表达力,其他人讨厌它。有些人严格遵循测试驱动开发成功发布软件,其他人在项目结束时简单地添加几个端到端测试,许多人处于这些极端之间的某个位置。
我见过使用所有这些不同方法的项目发布并维护成功的软件。
所以,再次强调,我的目标不是说服你我的编码方式是唯一的方法,而是向你展示(特别是年轻的开发者,他们容易被“Clean Code”这样的术语吓倒),你可以使用多种不同的方法来拥有成功的编程生涯,而我的方法就是其中之一。
TLDR
本文将讨论的三个“脏”编码实践是:
- (某些)大函数其实是好的
- 更喜欢集成测试而非单元测试
- 保持类/接口/概念数量最小
如果你想跳过文章的其余部分,这就是要点。
我喜欢大函数
我认为大函数是可以的。事实上,我认为代码库中 某些 大函数通常是 好事。
这与 Clean Code 相反,后者说:
“函数的第一条规则是它们应该小。第二条规则是它们应该比那更小。” Clean Code
当然,这总是取决于我正在做的工作类型,但通常我倾向于将函数组织成以下几类:
- 几个大型“核心”函数,这是模块的真正核心。我不对这些函数的代码行数 (LOC) 设置上限,尽管当它们超过 200-300 LOC 时,我会开始感到有点内疚。
- 相当数量的“支持”函数,通常在 10-20 LOC 范围内
- 相当数量的“实用”函数,通常在 5-10 LOC 范围内
作为一个“核心”函数的例子,考虑 htmx 中的 issueAjaxRequest()。这个函数几乎有 400 行长!
绝对不干净!
然而,在这个函数中,有很多上下文需要保持,并且它列出了一系列必须以相当线性方式进行的特定步骤。将它拆分成其他函数不会有任何重用,我认为这样做会损害函数的清晰度(对我来说,调试性也很重要)。
重要的事情应该大
我喜欢大函数的一个主要原因是,我认为在软件中,在其他条件相同的情况下,重要的事情应该大,而不重要的事情应该小。
考虑“干净”代码与“脏”代码的可视化表示:
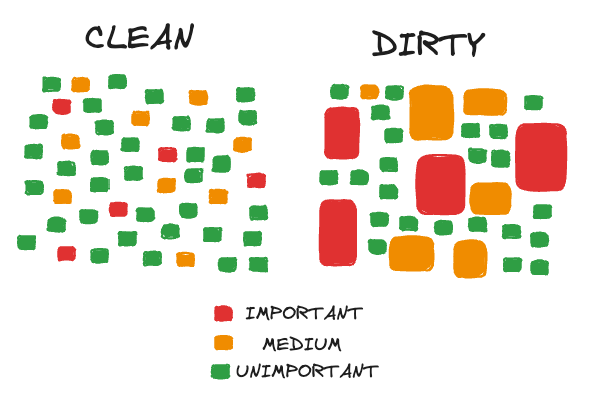
当你将函数拆分成许多大小相等的、小的实现时,你最终会将实现的重要部分分散在模块中,即使它们在一个更大的函数中表达得很好。
一切看起来都一样:一个函数签名定义,后跟一个 if 语句或 for 循环,也许一两个函数调用,然后返回。
如果你允许重要的“核心”函数更大,就更容易从函数的海洋中挑选出它们,它们显然很重要:看看它们,它们很大!
此外,所有类别的函数总体上更少,因为大部分代码已经合并到更大的函数中。较少的代码行 dedicated to 特定类型签名(这些签名可能会随时间变化),并且更容易将重要函数(甚至中等重要的函数)的名称和签名记在脑海中。当你这样做时,你整体的 LOC 也会更少。
我更喜欢进入一个新的“脏”代码模块:我会更快地理解它,并更容易记住重要部分。
实证证据
关于理想函数大小的实证(软件中的可怕词汇!)证据呢?
在 Code Complete 的 第 7 章,第 4 节 中,Steve McConnell 列出了一些支持和反对较长函数的证据。结果是混合的,但许多他引用的研究显示,对于 较大 而非较小的函数,错误每行的指标更好。
还有 更新的研究,它们主张较小的函数(<24 LOC),但重点关注它们所谓的“变更易感性”。当谈到 bug 时,它们说:
SLOC 与 bug 易感性(即 #BuggyCommits)之间的相关性显著低于四个变更易感性指标。
当然,更长的函数包含更多代码,因此 bug 易感性 每行代码 的相关性会更低。
真实世界示例
来看一些来自真实世界、复杂且成功的软件的示例?
考虑 SQLite 中的 sqlite3CodeRhsOfIn() 函数,这是一个流行的开源数据库。它看起来超过 200 LOC,在 SQLite 代码库中走一圈会发现许多其他大函数的示例。SQLite 以极高质量和非常良好的维护而闻名。
或者考虑 Google Chrome 网页浏览器中的 ChromeContentRendererClient::RenderFrameCreated() 函数。也看起来超过 200 LOC。再次,在代码库中戳一戳会给你很多其他长函数来看。Chrome 正在解决软件中最难的问题之一:成为一个好的通用超媒体客户端。然而它们的代码在我看来并不很“干净”。
接下来,考虑 Redis 中的 kvstoreScan() 函数。较小,大约 40 LOC,但仍然远大于 Clean Code 所建议的。在 Redis 代码库中快速扫描会提供许多其他“脏”示例。
这些都是基于 C 的项目,所以也许小函数规则只适用于面向对象语言,比如 Java?
好的,看看 IntelliJ 的 CompilerAction 类中的 update() 函数,大约 90 LOC。再次,在它们的代码库中戳一戳会揭示许多其他超过 50 LOC 的大函数。
SQLite、Chrome、Redis 和 IntelliJ……
这些都是重要、复杂、成功且维护良好的软件组件,然而我们在所有这些中都能找到大函数。
现在,我不想暗示这些项目中的任何工程师都同意本文的观点,但我觉得我们有一些相当好的证据表明,在软件项目中较长的函数是可以的。可以说,只是为了保持小而拆分函数是没有必要的。当然,你可以出于其他原因考虑这样做,比如代码重用,但仅仅为了小而小似乎没有必要。
我更喜欢集成测试而非单元测试
我是测试的忠实粉丝,并强烈推荐将测试软件作为构建可维护系统的一个关键组成部分。
htmx 本身之所以可能,是因为我们有一个好的 测试套件,它帮助我们确保在开发过程中库保持稳定。
如果你查看 测试套件,你可能会注意到 单元测试 的相对缺乏。我们几乎没有直接调用 htmx 对象上函数的测试。相反,测试主要是 集成测试:它们设置一个特定的 DOM 配置,带有一些 htmx 属性,然后,例如,点击一个按钮并验证 DOM 状态的某些事情。
这与 Clean Code 推荐的广泛 单元测试 以及测试优先开发相反:
第一定律 在编写失败的单元测试之前,你不得编写生产代码。 第二定律 你不得编写比足以失败更多的单元测试,不编译就是失败。 第三 定律 你不得编写比足以通过当前失败测试更多的生产代码。
我通常避免做这种事,尤其是在项目早期。早期你往往不知道领域正确的抽象是什么,你需要尝试几种不同的方法来弄清楚你在做什么。如果你采用测试优先方法,你最终会得到一堆在探索问题空间、寻找正确抽象时会崩溃的测试。
此外,单元测试鼓励对每个你编写的函数进行详尽测试,所以你往往会得到更多与特定实现绑定的测试,而不是代码模块的高级 API 或概念想法。
当然,你可以并且应该在改变事情时重构你的测试,但现实是,一个大型且不断增长的测试套件在项目中会产生自己的质量和动力,尤其当其他工程师加入时,会使更改越来越困难。你最终会为测试代码创建测试助手、模拟等。
所有这些代码和复杂性随着时间推移往往会将你锁定在特定实现中。
脏测试
我在许多项目中偏好的方法是,在项目早期做一些单元测试,但不是很多,并等到模块的核心 API 和概念已经晶化。
在那时,我然后用集成测试详尽测试 API。
根据我的经验,这些集成测试比单元测试更有用,因为即使你改变实现,它们也会保持稳定和有用。它们不那么与当前代码库绑定,而是表达更高层次的不变式,这些不变式更容易在重构中存活。
我还发现,一旦你有一些更高层次的集成测试,你就可以进行测试驱动开发,但是在更高层次:你不考虑代码单元,而是你想要实现的目标 API,为该 API 编写测试,然后以你认为合适的方式实现它。
所以,我认为你应该等到项目后期再承诺一个大型测试套件,并且该测试套件应该在比测试优先开发建议的更高层次上完成。
一般来说,如果我可以编写一个更高层次的集成测试来演示一个 bug 或功能,我会尝试这样做,希望更高层次的测试在项目中具有更长的保质期。
我倾向于最小化类
我使用的另一个编码策略是我通常努力最小化项目中的类/接口/概念数量。
Clean Code 并没有明确说你应该最大化系统中的类数量,但它做出的许多推荐往往会导致这种结果:
- “更喜欢多态而非 If/Else 或 Switch/Case”
- “类的第一条规则是它们应该小。第二条规则是它们应该比那更小。”
- “单一职责原则 (SRP) 规定,一个类或模块应该只有一个改变的原因。”
- “你可能首先注意到的是程序变长了。它从一页多一点变成了近三页。”
与函数一样,我不认为类应该特别小,或者你应该更喜欢多态而非一个简单的(甚至长而笨拙的)if/else 语句,或者给定的模块或类应该只有一个改变的原因。
我觉得这里的最后一句是一个好提示:你往往会得到更多代码,这对系统可能没有真正的好处。
“上帝”对象
你经常会听到人们批评 “God objects” 的想法,我当然能理解这种批评的来源:一个不连贯的类或模块,带有大量不相关函数的混乱,显然是一件坏事。
然而,我认为对“上帝”对象的恐惧往往会导致相反的问题:过度分解的软件。
为了平衡这种恐惧,让我们来看看我最喜欢的软件包之一,Active Record。
Active Record 提供了一种将 Ruby 对象映射到数据库的方法,它被称为 Object/Relational Mapping 工具。
在我看来,它在这方面做得很好:它使简单的事情简单,中等难度的事情足够简单,当需要时,你可以轻松切换到原始 SQL。
(这是一个我称之为 “layering” API 的绝佳示例。)
但 Active Record 对象并不仅擅长这个:它们还在 Rails 的 视图层 中提供优秀的 HTML 构建功能。它们不包括 特定于 HTML 的功能,但它们确实提供在视图端有用的功能,例如提供一个 API 来检索错误消息,甚至是字段级别的。
当你编写 Ruby on Rails 应用程序时,你只需将 Active Record 实例传递到视图/模板中。
将此与更重度分解的实现进行比较,其中验证错误作为自己的“关注点”处理。现在,你需要传递(或至少访问)两个不同的东西才能正确生成 HTML。在 Java 社区中采用 DTO 模式并不罕见,并有另一组完全独立于 ORM 层的对象传递到视图。
我喜欢 Active Record 的方法。从纯主义视角来看,它可能没有 分离关注点,但 我的 关注点往往是将数据从数据库获取到 HTML 文档中,而 Active Record 出色地完成了这项工作,而无需我处理沿途的一堆其他对象。
这有助于我最小化系统中需要处理的对象的总数。
某些功能会渗入模型中,可能有点“视图”风味吗?
当然,但这不是世界末日,它减少了我必须处理的层数和概念数。有一个类处理从数据库检索数据、持有领域逻辑并作为向视图层呈现信息的容器,这对我来说大大简化了事情。
结论
我给出了三个我的脏编码方法的示例:
- 我认为(某些)大函数其实是好的
- 我更喜欢集成测试而非单元测试
- 我喜欢保持类/接口/概念数量最小
我再次呈现这个,不是为了说服 你 以 我 的方式编码,或者暗示我的编码方式是“最优”的。
相反,这是为了给你,尤其是你们这些年轻的开发者,一个感觉,你不必按照许多思想领袖建议的方式编写代码,就能拥有成功的软件生涯。
如果有人称你的代码为“脏”,你不必感到害怕:很多非常成功的软件都是这样编写的,如果你专注于 软件工程 的 核心理念,你很可能尽管“脏”而成功,甚至可能因为它而成功!